
My brother and I continued our peer conference series meant to explore the experiences of serious testers with AI and subject them to scrutiny. We call this the Workshop on AI in Testing (WAIT). Our goal is to help foster a community of testers who can credibly claim expertise in both testing AI and using AI in testing.
We held the second one on May 18-19, 2024. Here’s what happened.
Attendees
- Jon Bach
- James Bach
- Michael Bolton
- Julie Calboutin
- Alexander Carlsson
- Ben Simo
- Carl Brown
- Bernie Berger
- Olesia Stetsiuk
- Mario Colina
- Karen Johnson
- Nate Custer
This LAWST-style conference was held over Zoom, in the Pacific time zone.
Jon Bach facilitated. I was content owner (that means I was responsible to keeping people on topic and helping the best content to come out of the experience reports).
Content Owner Statement, James Bach
Michael and I presented our analysis of how testing AI is different than testing other kinds of software.
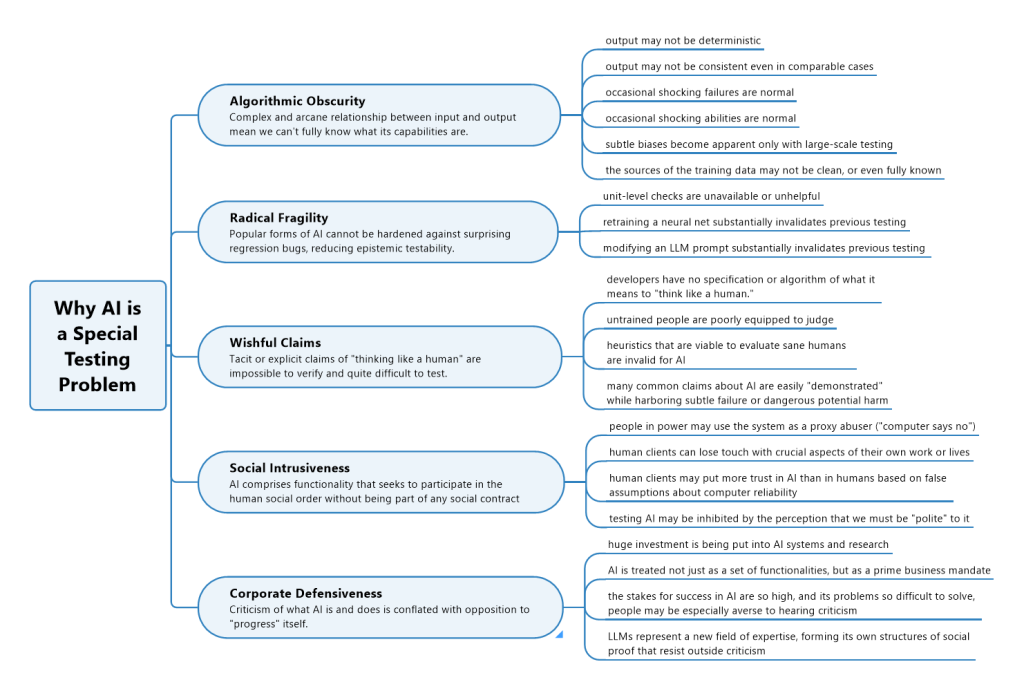
This was meant as a heuristic to focus the conversation, but to quickly became the subject of review and discussion, leading to several changes. Initially it had four branches, but I was persuaded by the group to add the fifth: corporate defensiveness. This is not so much special to AI as it is special to any new and heavily hyped technology. Still, hype is where we are with AI, so it is indeed part of the challenge faced by testers who dare to report bugs on AI products.
A few notes:
- Each of these items represents a challenge above and beyond that which we face with ordinary software– even very complex and large scale software.
- “Epistemic testability” means testability that results from already mostly knowing the status of a product. It is obviously easier to test a product that has been tested before and hasn’t changed much since then. When DevOps people extol the virtues of frequent incremental releases they are trying to maximize epistemic testability.
- Most vendors who include LLM functionality in products seem to expect users to accept AI into our social order as humans. This is dangerous. To some of us, it is infuriating and unacceptable. As testers, it’s difficult to test such products because what we expect from them is poorly defined and vendors seem utterly uninterested in defining it. It reminds me of the early days of the commercialization of radium: vendors packaged the glowing subtance in innumerable forms without any regard for the danger it posed. It was even sold as a cancer-causing toothpaste!
Experience Report #1, Carl Brown
Carl Brown presented a walkthrough of his experience debunking claims made by Cognition.ai about their tool called “Devin,” which they claim is “the world’s first AI software engineer.”
Carl’s experience report was not particularly long, but the questioning and commenting lasted all day. This is typical for the first ER of a peer conference, because people tend to use the first ER to bring up every topic they care about which might possibly relate. This is why I wanted Carl to go first: he’s used to taking heat.
He began with his analysis of Devin, then I asked him to tell us about his experience of analyzing Devin. In other words, what was his process and how did he arrive at that process? His approach was that he attempted to perform the same task that Devin allegedly performed. He then compared his experience and choices with Devin’s. He found that Devin performed a lot of unnecessary actions, including creating bugs in scripts that were not even needed, and then fixing bugs in those same unnecessary scripts.
Among the things we discussed were Carl’s ideas about why his video went viral and what that says about the AI hype cycle; and how he decided that his approach to solving the problem that Devin tried to solve was better than what Devin did. We also talked a lot about how challenging it is to oppose bad AI products, because of the extreme effort and time it takes to carefully review AI output, versus how cheap it is to produce. Critical thinkers become overwhelmed.
Experience Report #2, Olesia Stetsiuk
Our next ER came from Olesia Stetsiuk from Kyiv. Olesia has a background in hard science, which showed during her technical and analytical description of how her team designed and tested an LLM-based data analysis system. For confidentiality reasons she could not share every salient detail with us. However, she was able to provide enough so that we could understand the architecture and theory behind the system.
They developed several versions, all experimental and as yet not deployed for routine use.
One version allows a business user to ask a free form question about a data set. The system then creates a Python program to perform a visualization or analysis as needed, runs the program, and if the program doesn’t without throwing an error, regenerates the code until it runs cleanly. The team tested this approach by hand checking the code that was generated. They found for some questions the method produced good results. For others, the results were inconsistent, and for still others the generated code was never acceptable. This is an important issue that speaks to the problem of algorithmic obscurity as well as radical fragility: Just because the AI does something pleasing in one data set or for one prompt does not imply that it is reliable for any other prompt or data set. The reliability landscape for LLMs looks like the Mandlebrot Set. It could take a massive amount of time and computational resources even to concoct heuristics and advisories that would allow the product to be used safely.
Another version used LLMs to generate questions about a data set. They ran it in a loop until fewer and fewer new questions were being generated. The idea was to then feed these questions into the first system and create a sort of encyclopedia of pre-answered questions.
Under questioning, the conference delegates raised many concerns about these approaches. To her credit, Olesia responded with openness, patience, and epistemic humility. She reminded us that this was an experiment and that she didn’t know if it would result in a usable system.
Experience Report #3, Mario Colina
Mario, connecting from Montreal, reported on his attempt to use ChatGPT-4o to analyze a technical diagram.
He was surprised at how well it seemed to make sense of the graphical elements of the diagram, although close inspection showed it made a puzzling mistake by interpreting exactly the same graphical pattern, which showed up in two places, in two different ways. Since the diagram was using a formal notation that was apparently included in ChatGPT’s training data, this kind of error seems to indicate that LLMs can’t be trusted to ignore the text in a diagram and reason strictly about its logical structure.
Michael Bolton performed the same experiment with the same prompt and diagram, during the open season discussion. He received results which were different from and inconsistent with those that Mario received. Later, Michael and I tested our hypothesis that shuffling arbitrary text labels on a diagram, without changing any of the semantics of the diagram, causes ChatGPT to interpret the diagram differently in a manner that would not fool a human. The human would say “these labels don’t make sense, I think there is an error here.”
It is impressive that ChatGPT can read and interpret diagrams at all, even a little. However, I kept thinking of a dog owner who claims that his dog is an accomplished chef. Incredulous, you order Beef Wellington. After a few minutes, the dog emerges from the kitchen balancing a plate of scrambled eggs on its nose. They are good scrambled eggs, with only a little bit dirt mixed in. You politely ignore the tennis ball offered as garnish. When you complain, the dog’s owner says “But isn’t it amazing that he made you eggs?! Why are you so negative?”
I call this the dog chef problem. The moral is: we can be impressed with something and yet also admit that it is nowhere near good enough.
Leave a Reply